Today, kids, we are going to download iTunes U course almost exclusively from the command line.
Why
The easiest way to do that is to use iTunes to download all that for you. Unfortunately, while I have iPod/iPad in my home ecosystem, I don’t have any Mac computers. Thus, I’m running iTunes in a virtual machine on Windows. Imagine my user experience from such combination. Pure pain and suffering.
There wouldn’t be this post if it was all smooth. For unknown reasons my iTunes doesn’t save downloaded video files. I can see it’s downloading them, I can see the temp file growing, but when it’s done, puff, I can’t find the file anywhere. Luckily, there is a solution. It is a pity but you still need iTunes for a couple of steps.
How
OK, let’s do it. Say, you found an interesting course on iTunes U:
Step 1. Subscribe to the course in iTunes
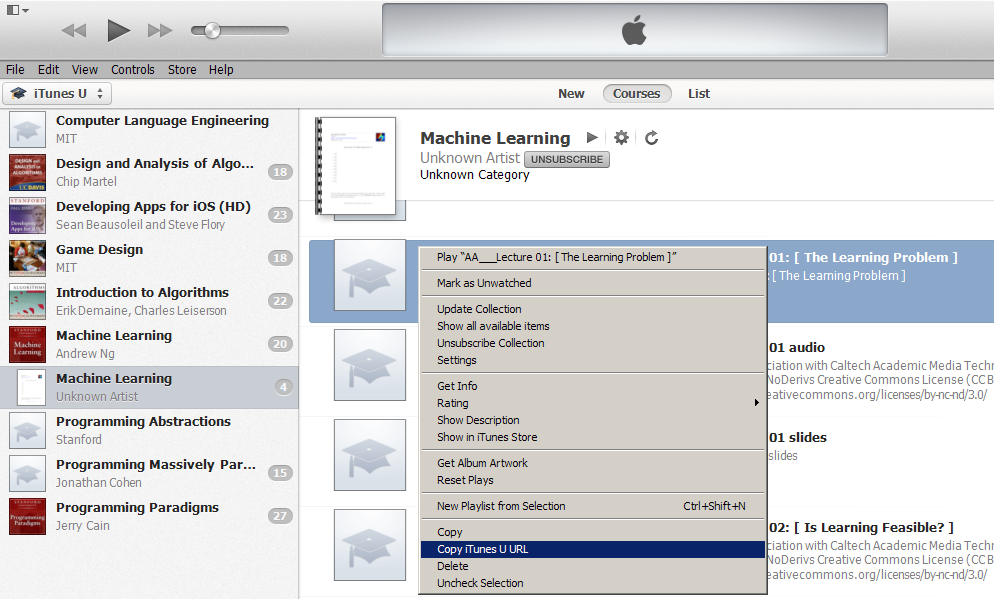
Step 2. Copy course url
Click on any item in the course materials list and select “Copy iTunes U URL”.
NB: There is iTunes U Course Manager web page and I presume you might get the feed URL there (though I really doubt you can). However, my country isn’t enjoying Apple’s favour.

Step 3. Download the feed
wget -O list.xml https://p1-u.itunes.apple.com/WebObjects/LZStudent.woa/ra/feed/CODBABB3ZC
Step 4. Extract links and titles
The feed contains feed/entry items in the format as follows:
<?xml version="1.0" encoding="UTF-8"?>
<feed xmlns="http://www.w3.org/2005/Atom" xmlns:itms="http://www.itunes.com/dtds/itunesu-1.0.dtd">
<title type="text">Machine Learning</title>
<subtitle type="text"><div><div><strong>A real Caltech course...</subtitle>
<updated>2013-06-12T00:19:12PDT</updated>
<link rel="alternate" type="text/html"
href="https://p1-u.itunes.apple.com/WebObjects/LZStudent.woa/ra/courses/CODBABB3ZC"/>
<id>1/CODBABB3ZC</id>
<itms:courseid>CODBABB3ZC</itms:courseid>
<itms:auditUrl>https://itunesu.itunes.apple.com/audit/CODBABB3ZC</itms:auditUrl>
<entry>
<author>
<name>Dr. Yaser Abu-Mostafa</name>
</author>
<title type="html"><![CDATA[AC___Lecture 01 slides]]></title>
<id>1/CODBABB3ZC/MAES7ECEVA</id>
<updated>2013-06-11T23:25:24PDT</updated>
<published>2012-06-14T15:07:36PDT</published>
<summary type="html"><![CDATA[AC___Lecture 01 slides]]></summary>
<link rel="enclosure" type="application/pdf"
href="http://a1372.phobos.apple.com/us/r30/CobaltPublic/v4/35/56/6a/35566a02-1e0a-3db8-17e2-69be6445ba9b/208-5815754981465838988-ACsld01.pdf"
length="300673"/>
</entry>
...
It is very convenient to use xmlstartlet to extract titles and links from the feed. Note, however, that xmlstartlet is very picky to namespace (thanks to this answer). Extraction command will look as follows:
xml sel -N x="http://www.w3.org/2005/Atom" -t -m //x:entry -v x:title -o "|" -v x:link/@href -n list.xml > fmt.txt
Step 5. Download the course
Now all that is left is to read titles and links and download them. I prefer to use aria2c
IFS='|' && while read a b; do n=$a.${b##*.}; aria2c --allow-overwrite=false --auto-file-renaming=false -o $n $b; done < fmt.txt
${b##*.} is a command to get filename extension (see this
and this)